简述
在这一章里,所有的事情都要集中起来。我们将编写drawFrame函数,该函数将在主循环中被调用,以将三角形置于屏幕上。创建函数并从mainLoop调用它.
1 | void mainLoop() { |
一. 同步
drawFrame函数将执行以下操作:
- 从交换链获取一个映像
- 在framebuffer中以该图像作为附件执行命令缓冲
- 将图像返回到交换链以便显示
这些事件都是使用单个函数调用设置的,但它们是异步执行的。函数调用将在操作实际完成之前返回,并且执行的顺序也未定义。因为每个操作都依赖于前一个完成,所以需要同步机制。
有两种同步交换链事件的方法:栅栏和信号量。
它们都是可以用于协调操作的对象,方法是让一个操作信号和另一个操作等待栅栏或信号量从无信号状态变为有信号状态。
不同的是,你可以通过vkWaitForFences来访问fences的状态,而信号量却不能。
fence主要用于通过呈现操作同步应用程序本身,而信号量用于在命令队列内或跨命令队列同步操作。我们想要同步draw命令和表示的队列操作,这使得信号量最适合。
1.1 信号量同步
信号量是一种同步原语,可以用来在提交给队列的批之间插入依赖关系。信号量有两种状态——有信号的和无信号的。一个信号量的状态可以在一批命令执行完成后发出信号。批处理可以在开始执行前等待信号量变成有信号的,也可以在批处理开始执行前等待信号量变成无信号的。
与Vulkan中的大多数对象一样,信号量是内部数据的接口,通常对应用程序是不透明的。这个内部数据被称为信号量的有效负载。但是,为了能够与当前设备之外的代理进行通信,必须能够将有效负载导出为一种普遍理解的格式,然后再从该格式导入。信号量的内部数据可以包括对任何资源的引用,以及与在该信号量对象上执行的信号或非信号操作相关的待定工作。
下面提供了向信号量导入和导出内部数据的机制。这些机制间接地使应用程序能够跨进程和API边界在两个或多个信号量和其他同步原语之间共享信号量状态。
信号量由VkSemaphore句柄表示:VK_DEFINE_NON_DISPATCHABLE_HANDLE(VkSemaphore)
1 | VkResult vkCreateSemaphore( |
- device: 创建信号量的逻辑设备
- pCreateInfo: 指向VkSemaphoreCreateInfo结构体实例的指针,该结构体包含了如何创建信号量的信息
- pAllocator: 控制内存分配
- pSemaphore: 指向返回结果信号量对象的句柄。
创建时,信号量处于无信号状态。
1 | typedef struct VkSemaphoreCreateInfo { |
- sType: 此结构的类型,VK_STRUCTURE_TYPE_SEMAPHORE_CREATE_INFO
- pNext: 为空或指向特定于扩展的结构的指针
- flags: 当前API下无可用flag, 未来版本的Vulkan API或扩展可能会像对其他结构一样为flag和pNext参数添加功能
1.2 创建信号量 vkCreateSemaphore
需要一个信号量来表示图像已经获得并准备好呈现,还需要另一个信号量来表示渲染已经完成并可以进行呈现。创建两个类成员来存储这些信号量对象:
1 | VkSemaphore imageAvailableSemaphore; |
创建信号量需要填写VkSemaphoreCreateInfo,但是在当前版本的API中,除了sType之外实际上没有任何必需的字段:
1 | void initVulkan() { |
同理,信号量应该在程序结束时清除,当所有的命令都已经完成,不再需要更多的同步:
1 | void cleanup() { |
二. 从交换链获取图像
如前所述,在drawFrame函数中需要做的第一件事是从交换链中获取图像。回想一下,交换链是一个扩展特性,所以我们必须使用一个具有vk*KHR命名约定的函数:
1 | void drawFrame() { |
获取一个可用的可呈现图像使用,并检索该图像的索引,调用: vkAcquireNextImageKHR:
1 | VkResult vkAcquireNextImageKHR( |
- device: 提供逻辑设备句柄
- swapChain: 交换链对象的句柄, 从这个交换链中获取图像
- timeout: 指定如果没有可用的映像,函数将等待多长时间(以纳秒为单位)。
- semaphore: 是VK_NULL_HANDLE或者一个信号量
- fence: VK_NULL_HANDLE或fence to signal。
- pImageIndex: 一个指向uint32_t的指针, 用于输出可用的交换链映像的索引, 索引指的是swapChainImages数组中的VkImage。我们将使用这个索引来选择正确的命令缓冲区。
当成功时,vkAcquireNextImageKHR从swapchain获得一个应用程序可以使用的图像,并将pImageIndex设置为该图像在swapchain中的索引。表示引擎在获取图像时可能还没有完成对图像的读取,因此应用程序必须使用信号量和/或栅栏来确保图像布局和内容在表示引擎读取完成之前不会被修改。如果semaphore不是VK_NULL_HANDLE,应用程序可能会认为,一旦vkAcquireNextImageKHR返回,semaphore引用的信号量信号操作已经提交执行。图像获取的顺序取决于实现,并且可能与图像呈现的顺序不同。
如果timeout为0,则vkAcquireNextImageKHR不会等待,并且会成功获取镜像,或者失败并返回VK_NOT_READY,如果没有可用的镜像。如果指定的超时时间在获取镜像之前过期,vkAcquireNextImageKHR将返回VK_TIMEOUT。如果timeout是UINT64_MAX,超时时间被认为是无限的,vkAcquireNextImageKHR将阻塞直到一个图像被获取或一个错误发生。
如果应用程序当前获取的(但尚未呈现的)图像数量小于或等于swapchain中的图像数量与vksurfacecabiltieskhr::minImageCount值之间的差值,则最终会获得一个图像。如果当前获取的图像数量大于此值,则不应该调用vkAcquireNextImageKHR;如果是,timeout不能是UINT64_MAX。
如果一个图像成功获得,vkAcquireNextImageKHR必须要么返回VK_SUCCESS,要么返回VK_SUBOPTIMAL_KHR,如果交换链不再完全匹配表面属性,但仍然可以用于表示。
三. 提交指令缓冲区
队列提交和同步是通过VkSubmitInfo结构中的参数配置的。
1 | typedef struct VkSubmitInfo { |
- sType: 此结构的类型,VK_STRUCTURE_TYPE_SUBMIT_INFO
- pNext: 为空或指向特定于扩展的结构的指针
- waitSemaphoreCount: 执行批处理的命令缓冲区之前需要等待的信号量的数量
- pWaitSemaphores: 指向VkSemaphore句柄数组的指针,在这个批处理的命令缓冲区开始执行之前,要等待该句柄。如果提供了等待的信号量,则定义一个信号量等待操作。
- pWaitDstStageMask: 指向每个对应的信号量等待将发生的管道阶段数组的指针
- commandBufferCount: 批处理中要执行的命令缓冲区的数量
- pCommandBuffers: 指向要在批处理中执行的VkCommandBuffer句柄数组的指针
- signalSemaphoreCount: 在pCommandBuffers中指定的命令完成执行后要发出信号的信号量的数量
- pSignalSemaphores: 指向VkSemaphore句柄数组的指针,当这个批处理的命令缓冲区完成执行时,VkSemaphore句柄数组将发出信号。如果提供了要发送信号的信号量,它们定义了一个信号量信号操作。
命令缓冲区在pCommandBuffers中出现的顺序用于确定提交顺序,因此所有的隐式排序都保证遵守它。除了这些隐式排序保证和任何显式同步原语之外,这些命令缓冲区可能会重叠或以其他方式乱序执行。
1 | // 前三个参数指定在执行开始之前等待哪些信号量,以及在管道的哪个阶段等待。 |
使用vkqueuessubmit将命令缓冲区提交到图形队列。当工作负载更大时,该函数接受一个VkSubmitInfo结构数组作为效率参数。
最后一个参数引用一个可选的fence,该fence将在命令缓冲区完成执行时发出信号。我们使用信号量进行同步,所以我们将传递一个VK_NULL_HANDLE。
1 | VkResult vkQueueSubmit( |
- queue: 命令缓冲将被提交到的队列
- submitCount: 提交数组pSubmits中的元素数量
- pSubmits: 指向VkSubmitInfo结构数组的指针,每个结构都指定了一个命令缓冲区提交批处理
- fence: 可选的fence句柄,一旦所有提交的命令缓冲区完成执行,就会发出信号。如果fence不是VK_NULL_HANDLE,则定义一个fence信号操作
提交可能是一个高开销的操作,应用程序应该尽可能少的调用vkqueuessubmit来批量处理。
四. Subpass依赖
渲染通道中的子通道会自动处理图像布局的转换。这些转换由子传递依赖项控制,子传递依赖项指定子传递之间的内存和执行依赖项。
我们现在只有一个Subpass,但是在这个Subpass之前和之后的操作也被算作隐式的“Subpasses”。
有两个内置的依赖关系负责渲染通道开始和结束的转换,但前者没有在正确的时间发生。它假设转换发生在管道的开始,但是我们在那一点还没有获得图像!
有两种方法来处理这个问题:
- 将imageAvailableSemaphore的等待阶段更改为VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT,以确保渲染通道直到图像可用时才开始
- 让渲染通道等待VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT阶段。
在这里使用第二种方法,因为这是一个很好的方式来了解子传递依赖项及其工作方式。Subpass依赖在VkSubpassDependency结构中指定。
在createRenderPass函数中添加一个:
1 | VkSubpassDependency dependency = {}; |
特殊值VK_SUBPASS_EXTERNAL指的是在渲染传递之前或之后的隐式子传递,这取决于它是在srcSubpass还是dstSubpass中指定的。
索引0指向我们的子通道,它是第一个也是唯一一个。dstSubpass必须始终高于srcSubpass,以防止依赖关系图中的循环。
五. 显示
绘制框架的最后一步是将结果提交回交换链,使其最终显示在屏幕上。
在应用程序可以呈现一个图像之前,图像的布局必须转换为VK_IMAGE_LAYOUT_PRESENT_SRC_KHR布局,或者对于一个共享的可呈现图像,必须转换为VK_IMAGE_LAYOUT_SHARED_PRESENT_KHR布局。
5.1 VkPresentInfoKHR
1 | typedef struct VkPresentInfoKHR { |
- sType: 此结构的类型,VK_STRUCTURE_TYPE_PRESENT_INFO_KHR
- pNext: 为空或指向特定于扩展的结构的指针
- waitsemaphore: 在发出当前请求之前等待的信号量的数量, 可能是零。
- pwaitsemaphres: 空的或指向带有waitsemaphore条目的VkSemaphore对象数组的指针,它指定了在发出当前请求之前需要等待的信号量。
- swapchainCount: 指令提供给交换链的数量
- pSwapchains: 指向带有swapchainCount条目的VkSwapchainKHR对象数组的指针。给定的交换链不能在此列表中出现多次。
- pImageIndices: 指向每个swapchain的可呈现图像数组的索引数组的指针,其中包含swapchainCount条目。这个数组中的每个条目都标识要在pSwapchains数组中的相应条目上显示的图像。
- results: 指向带有swapchainCount条目的VkResult类型元素数组的指针。不需要每个swapchain结果的应用程序可以对结果使用NULL。如果非null,则results中的每个条目都将被设置为VkResult,以表示与pSwapchains中的相同索引相对应的交换链。
5.2 显示设置
通过drawFrame函数末尾的VkPresentInfoKHR结构来配置显示相关设置:
1 | VkPresentInfoKHR presentInfo = {}; |
现在编译运行一下我们的程序:
ohhhh!!!!整整一千多行的代码,终于不是黑糊糊的窗口了。
当启用验证层时,程序在关闭时就会崩溃。从debugCallback打印到终端的消息告诉我们为什么:
记住,drawFrame中的所有操作都是异步的。这意味着当我们退出mainLoop中的循环时,绘图和表示操作可能仍然在进行。当这种情况发生时,清理资源就可能带来异常。
要解决这个问题,我们应该等待逻辑设备完成操作,然后退出mainLoop并销毁窗口:
1 | void mainLoop() { |
5.2.1 vkQueuePresentKHR
在将所有渲染命令排队并将图像转换到正确的布局后,要将图像排队显示,调用:
1 | VkResult vkQueuePresentKHR( |
- queue是一个能够在与图像交换链相同的设备上显示到目标表面平台的队列。
- pPresentInfo是一个指向VkPresentInfoKHR结构体的指针,该结构体指定了表示的参数。
应用程序不需要按照获取图像的顺序来呈现图像——应用程序可以任意地呈现当前获取的任何图像。
六. Frames in flight
如果在启用了验证层的情况下运行应用程序,并且监视应用程序的内存使用情况,则可能会注意到它正在缓慢增长。
原因是应用程序正在使用drawFrame函数快速提交工作,但实际上并没有检查是否有任何工作完成。如果CPU提交工作的速度快于GPU不能跟上的工作,那么队列将缓慢地填满工作。 更糟糕的是,我们同时对多个帧重用了imageAvailableSemaphore和renderFinishedSemaphore。
解决此问题的简单方法是提交后等待工作完成,例如使用vkQueueWaitIdle:
1 | void drawFrame() { |
但是,我们可能无法以这种方式最佳地使用GPU,因为整个图形流水线现在一次只能使用一帧。 当前帧已经经过的阶段是空闲的,可能已经用于下一帧。 现在,我们将扩展我们的应用程序,以允许在运行多个frame的同时仍限制堆积的工作量。
首先在程序顶部添加一个常量,该常量定义应同时处理多少帧, 以及每个frame应具有自己的一组信号:
1 | const int MAX_FRAMES_IN_FLIGHT = 2; |
同理,drawFrame也需要修改:
1 | void drawFrame() { |
这里的currentFrame可以通过取模来获取: currentFrame = (currentFrame + 1)%MAX_FRAMES_IN_FLIGHT
通过使用模(%)运算符,我们确保帧索引在每个MAX_FRAMES_IN_FLIGHT排队的帧之后循环。
6.1 fence机制
尽管我们现在已经设置了必需的对象以方便同时处理多个帧,但实际上并没有阻止提交超过MAX_FRAMES_IN_FLIGHT个对象。 现在只有GPU-GPU同步,没有CPU-GPU同步来跟踪工作的进行情况。 我们可能正在使用第0帧对象,而第0帧仍在显示中!
为了执行CPU-GPU同步,Vulkan提供了第二种类型的同步原语,称为fences。 在可以发信号并等待信号的意义上,fence与信号相似,但是这次我们实际上在自己的代码中等待信号。 我们首先为每个框架创建一个fence:
1 | std::vector<VkSemaphore> imageAvailableSemaphores; |
因为fence也是同步机制,所以最好把同步对象的创建放在一起,吧createSemaphores改名成createSyncObjects:
1 | void createSyncObjects() { |
也要记得销毁fence.
1 | void cleanup() { |
现在使用fence进行同步。vkqueuessubmit调用包含一个可选参数,用于传递一个fence,当命令缓冲区执行完毕时,该fence应该被通知。我们可以用它来表示一个帧已经完成。
1 | void drawFrame() { |
vkWaitForFences函数接受一个fences数组,在返回之前等待其中任何一个或者所有的栅栏被通知。我们在这里传递的VK_TRUE表示我们希望等待所有的fence,但在单个fence的情况下,这显然无关紧要。就像vkAcquireNextImageKHR一样,这个函数也是需要一个超时。
与信号量不同,我们需要通过vkResetFences调用来手动将栅栏恢复到无信号状态。如果你现在运行这个程序,你会注意到一些奇怪的东西。应用程序似乎不再呈现任何东西。
这是因为在等一个还没被提交的fence! 这里的问题是,在默认情况下,fence是在无信号状态下创建的。这意味着如果我们以前没有用过fence,vkWaitForFences将会永远等下去。为了解决这个问题,我们可以改变fence的创建,在有信号的状态下初始化它,就像我们已经完成了初始帧的渲染一样:
1 | VkFenceCreateInfo fenceInfo = {}; |
程序现在应该可以正常工作了,内存泄漏也消失了! 我们已经实现了所有需要的同步,以确保排队的工作不超过两个帧。请注意,代码的其他部分,如最终的清理,可以依赖于更粗糙的同步,如vkDeviceWaitIdle,应该根据性能需求决定使用哪种方法。
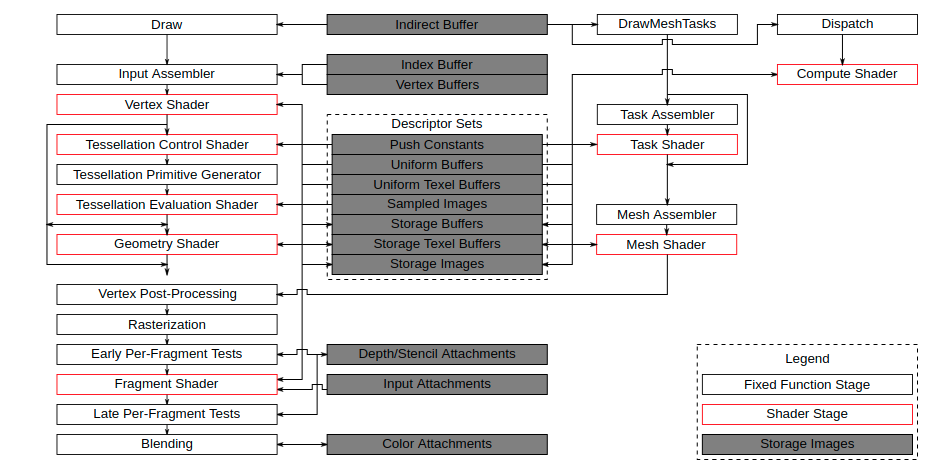
Vulkan管道的框图
七. 总结
现在我们已经写了一千多行的代码,总算把Vulkan的这一套简单的过了一遍。在继续后续学习之前,有必要先总结一下,巩固基础。
首先Vulkan是什么:Vulkan是一个低开销、跨平台的二维、三维图形与计算的应用程序接口(API)。本身是一个与平台无关的API,所以不包括用于创建显示渲染结果的窗口的工具。所以借助 GLFW (当然也可以是其他库如SDL)创建窗口。
下面是一个Vuklan应用一般流程的简述:
- 借助GLFW库,创建显示窗口。
- 创建Vulkan实例VkInstance
- 使用VkApplicationInfo和VkInstanceCreateInfo声明相关配置
- 调用 vkCreateInstance, 创建 vulkan 实例
- 如果是开发调试,可以启用验证层
- 实现调试回调函数
- 通过VkDebugUtilsMessengerCreateInfoEXT.pfnUserCallback绑定消息回调函数
- 通过CreateDebugUtilsMessengerEXT函数实例化DebugUtilsMessengerEXT
- 注意在不需要的时候显示销毁回调实例 PFN_vkDestroyDebugUtilsMessengerEXT
- 检索合适的物理设备
- 通过vkEnumeratePhysicalDevices获取本机物理显卡,并根据需要选择合适GPU
- 通过vkGetPhysicalDeviceProperties检查显卡的基本功能
- 查询vkGetPhysicalDeviceFeatures中可以被支持的feature
- 挑选需要的队列族
- 通过vkGetPhysicalDeviceQueueFamilyProperties获取物理显卡支持的队列,并挑选需要的队列
- 通过vkEnumeratePhysicalDevices获取本机物理显卡,并根据需要选择合适GPU
- 创建逻辑设备 VkDevice
- 首先将4.2.1中挑选的队列记录在VkDeviceQueueCreateInfo中,指定要创建的队列VkDeviceCreateInfo.pQueueCreateInfos
- 指定使用的设备功能(feature),比如几何着色器等
- 通过vkCreateDevice函数创建逻辑设备,注意在不需要的时候显示销毁逻辑设备(vkDestroyDevice)
- 队列是与逻辑设备一起自动创建的,直接通过vkGetDeviceQueue获取该逻辑设备上指定的队列即可(当逻辑设备被销毁时,会隐式清除设备队列)
- 创建Surface
- 启用VK_KHR_surface扩展,通过glfw的glfwCreateWindowSurface创建VkSurfaceKHR
- 创建交换链,即渲染缓冲区, 本质上是一个等待呈现给屏幕的图像队列
- 检查GPU是否支持交换链,VK_KHR_SWAPCHAIN_EXTENSION_NAME
- 使能设备VK_KHR_swapchain扩展
- 获取关于swap chain更多支持细节
- 基本Surface功能(交换链中的最小/最大图像数,图像的最小/最大宽度和高度)
- Surface的格式(像素格式,色彩空间)
- 可用的呈现模式
- 为交换链选择合适的设置,如Surface格式(颜色深度)、呈现模式(将图像“交换”到屏幕的条件)、交换范围(交换链中图像的分辨率)等
- 创建swap chain对象 VkSwapchainKHR
- 绑定窗口Surface
- 设置最小图像数量 minImageCount
- 选择合适的图像格式 imageFormat
- 选择合适的图像颜色空间 imageColorSpace
- 选择合适的图像分辨率 imageExtent
- 设置图像图层 imageArrayLayers
- 设置图像操作方式 imageUsage
- 选择图像呈现模式 presentMode
- 是否需要裁剪功能 clipped(VK_TRUE, VK_FALSE)
- 设置旧交换链的引用 oldSwapchain
- 获取交换链图像(VkImage)对象集合
- 创建渲染过程,Render Passes
- 通过vkCreateRenderPass创建,在不需要时通过vkDestroyRenderPass销毁
- 创建图形管道, 在Vulkan中,必须明确所有内容,从视口大小到颜色混合功能。有如下几个固定操作:
- 输入汇编程序(input assembler): 从指定的缓冲区收集原始顶点数据,也可以使用索引缓冲区重复某些元素,而不必复制顶点数据本身。
- 顶点着色器(vertex shader): 针对每个顶点运行,并且通常应用变换以将顶点位置从模型空间转换到屏幕空间。它还沿着管道传递每顶点数据。
- 曲面细分着色器(tessellation shaders): 根据特定规则细分几何体以提高网格质量。通常用于使砖墙和楼梯等表面在附近时看起来不那么平坦。
- 几何着色器(geometry shader): 在每个基元(三角形,直线,点)上运行,并且可以丢弃它或输出比原来更多的基元。类似于曲面细分着色器,但更灵活。但没有得到太多应用,因为大多数显卡的性能都不是很好。
- 光栅化阶段(rasterization stage): 将基元离散化为片段。这些是它们填充在帧缓冲区上的像素元素。在屏幕之外的片段都将被丢弃,顶点着色器输出的属性将在片段之间进行插值。由于深度测试,通常在这里也丢弃其他原始片段后面的片段。
- 片段着色器(fragment shader): 为存活的每个片段调用片段着色器,并确定片段写入哪些帧缓冲区以及使用哪些颜色和深度值。它可以使用来自顶点着色器的插值数据来完成此操作,其中可以包括纹理坐标和法线照明等内容。
- 颜色混合阶段(color blending stage): 应用操作来混合映射到帧缓冲区中的相同像素的不同片段。 fragment可以简单地相互覆盖,加起来或根据透明度进行混合。
- 输入汇编程序、光栅化和颜色混合阶段阶段被称为固定功能阶段。这些阶段允许使用参数调整其操作,但它们的工作方式是预定义的。
- 顶点着色器、曲面细分着色器、几何着色器和片段着色器阶段是可编程的,这意味着可以将代码上传到图形卡,以完全应用想要的操作。
- 例如,实现从纹理和光照到光线跟踪器的任何内容。这些程序同时在许多GPU内核上运行,以并行处理许多对象,如顶点和片段。,可以使用片段着色器
- 通过vkCreateGraphicsPipelines创建图形管道,指明渲染过程
- 创建帧缓冲区
- 调整帧缓冲区容器的大小以容纳所有交换链图像视图
- 指定帧缓冲区需要与哪个renderPass兼容。只能对与之兼容的渲染过程使用帧缓冲区,这意味着它们使用相同数量和类型的附件。
- attachmentCount和pAttachments参数指定应绑定到渲染过程pAttachment数组中相应附件描述的VkImageView对象。
- 帧缓冲区宽度和高度参数是交换链中获取的宽高
- 帧缓冲区的layers是指图像数组中的层数
- 在不需要时,通过vkDestroyFramebuffer销毁帧缓冲区
- 创建指令缓冲区,Vulkan必须在指令缓冲区对象中记录想要执行的所有操作
- 先创建创建指令缓冲池,Command pool
- 创建指令缓冲区,大小和帧缓冲一致
- 渲染和显示
- 从交换链获取一个映像
- 在framebuffer中以该图像作为附件执行命令缓冲,提交指令缓冲区
- 将图像返回到交换链以便显示
- 渲染显示的过程需要同步
好的,现在我们又加深了一遍印象,这其中诸多细节我们后续挖掘。