简述
虽然现在我们创建的顶点缓冲区工作正常,但是从CPU访问它的内存类型可能不是图形显卡本身读取的最佳内存类型,最理想的内存具有VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT位标志,并且通常不可由专用图形显卡上的CPU访问。而且我们上一篇最后实现的随鼠标移动的功能也没有考虑同步,简单一点,考虑读写分离。
现在创建两个顶点缓冲区:CPU可访问内存中的一个暂存缓冲区用于从顶点数组上传数据,最终顶点缓冲区位于设备本地内存中。然后我们将使用一个缓冲区复制命令将数据从暂存缓冲区移动到实际的顶点缓冲区。简单来说就是暂存缓冲区用于cpu写入,顶点缓冲区用于GPU读取数据。
参考资料
- Vulkan coordinate system http://vulkano.rs/guide/vertex-input
一. 传输队列
buffer copy命令需要支持传输操作的队列族,使用VK_QUEUE_TRANSFER_BIT表示。不过任何具有VK_QUEUE_GRAPHICS_BIT或VK_QUEUE_COMPUTE_BIT功能的队列家族都已经隐式支持VK_QUEUE_TRANSFER_BIT操作。在这些情况下,不需要实现在queueFlags中显式地列出它。
但可以尝试使用专门用于传输操作的不同队列族, 可以如下操作:
- 修改QueueFamilyIndices和findQueueFamilies来显式地查找具有VK_QUEUE_TRANSFER位的队列族,而不是VK_QUEUE_GRAPHICS_BIT位
- 修改createLogicalDevice以请求传输队列的句柄
- 为传输队列系列上提交的命令缓冲区创建第二个命令池
- 修改资源的共享模式为VK_SHARING_MODE_CONCURRENT,并指定图形和传输队列族
- 提交传输命令,如vkCmdCopyBuffer到传输队列,而不是图形队列
二. 暂存缓冲区
因为我们要创建多个VkBuffer,所以最好把共有的部分抽出,以避免代码累赘:
1 | // 传入必要参数 |
因为我们需要使用传输队列,所以注意stagingBuffer的usage是用的VK_BUFFER_USAGE_TRANSFER_SRC_BIT,而vertexBuffer现在用的是VK_BUFFER_USAGE_TRANSFER_DST_BIT!
vertexBuffer现在从设备本地的内存类型分配,这意味着我们不能使用vkMapMemory。但是,我们可以将数据从stagingBuffer复制到vertexBuffer。我们必须通过指定stagingBuffer的传输源标志和vertexBuffer的传输目标标志以及顶点缓冲区使用标志来表明我们打算这样做。
2.1 VkBufferUsageFlagBits
1 | typedef enum VkBufferUsageFlagBits { |
VkBufferUsageFlagBits设置的位可以指定缓冲区的使用行为:
- VK_BUFFER_USAGE_TRANSFER_SRC_BIT指定缓冲区可以用作传输命令的源(请参阅VK_PIPELINE_STAGE_TRANSFER_BIT的定义)。
- VK_BUFFER_USAGE_TRANSFER_DST_BIT指定缓冲区可以用作传输命令的目的地。
- VK_BUFFER_USAGE_UNIFORM_TEXEL_BUFFER_BIT缓冲区可用于创建一个VkBufferView,该视图适合占用VK_DESCRIPTOR_TYPE_UNIFORM_TEXEL_BUFFER类型的VkDescriptorSet槽位。
- VK_BUFFER_USAGE_STORAGE_TEXEL_BUFFER_BIT指定该缓冲区可以用来创建一个VkBufferView,该视图适合于占用VK_DESCRIPTOR_TYPE_STORAGE_TEXEL_BUFFER类型的VkDescriptorSet槽位。
- VK_BUFFER_USAGE_UNIFORM_BUFFER_BIT缓冲区可以用于VkDescriptorBufferInfo中,该缓冲区适合于占用VkDescriptorSet类型的VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER_DYNAMIC槽位。
- VK_BUFFER_USAGE_STORAGE_BUFFER_BIT指定该缓冲区可用于VkDescriptorBufferInfo中,该缓冲区适合于占用VkDescriptorSet类型的VK_DESCRIPTOR_TYPE_STORAGE_BUFFER_DYNAMIC槽位。
- VK_BUFFER_USAGE_INDEX_BUFFER_BIT指定该缓冲区适合作为buffer参数传递给vkCmdBindIndexBuffer。
- VK_BUFFER_USAGE_VERTEX_BUFFER_BIT指定缓冲区适合作为pBuffers数组的元素传递给vkCmdBindVertexBuffers。
- VK_BUFFER_USAGE_INDIRECT_BUFFER_BIT缓冲区适合作为buffer参数传递给vkCmdDrawIndirect、vkCmdDrawIndexedIndirect、vkCmdDrawMeshTasksIndirectNV、vkCmdDrawMeshTasksIndirectCountNV或vkCmdDispatchIndirect。它也适合作为VkIndirectCommandsTokenNVX的缓冲区成员,或VkCmdProcessCommandsInfoNVX的sequencesCountBuffer或sequencesIndexBuffer成员传递
- VK_BUFFER_USAGE_CONDITIONAL_RENDERING_BIT_EXT指定缓冲区适合作为buffer参数传递给vkCmdBeginConditionalRenderingEXT。
- VK_BUFFER_USAGE_TRANSFORM_FEEDBACK_BUFFER_BIT_EXT指定该缓冲区适合使用for binding作为vkCmdBindTransformFeedbackBuffersEXT的转换反馈缓冲区。
- VK_BUFFER_USAGE_TRANSFORM_FEEDBACK_COUNTER_BUFFER_BIT_EXT指定该缓冲区适合与vkCmdBeginTransformFeedbackEXT和vkCmdEndTransformFeedbackEXT一起用作计数器缓冲区。
- VK_BUFFER_USAGE_RAY_TRACING_BIT_NV指定缓冲区适用于vkCmdTraceRaysNV和vkCmdBuildAccelerationStructureNV。
- VK_BUFFER_USAGE_SHADER_DEVICE_ADDRESS_BIT指定缓冲区可以通过vkGetBufferDeviceAddress来检索缓冲区设备地址,并使用该地址从着色器访问缓冲区的内存。
2.2 VkMemoryPropertyFlags
1 | typedef enum VkMemoryPropertyFlagBits { |
- VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT: 指定使用这种类型分配的内存对于设备访问是最有效的。当且仅当内存类型属于设置了VK_MEMORY_HEAP_DEVICE_LOCAL_BIT的堆时,才会设置此属性。
- VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT: 指定使用这种类型分配的内存可以通过vkMapMemory映射给主机访问。
- VK_MEMORY_PROPERTY_HOST_COHERENT_BIT: 指定主机缓存管理命令vkFlushMappedMemoryRanges和vkInvalidateMappedMemoryRanges分别用于刷新主机对设备的写操作,或者使设备的写操作对主机可见。
- VK_MEMORY_PROPERTY_HOST_CACHED_BIT: 指定用这种类型分配的内存缓存在主机上。主机内存对非缓存内存的访问比对缓存内存的访问慢,但是非缓存内存总是与主机一致的。
- VK_MEMORY_PROPERTY_LAZILY_ALLOCATED_BIT: 指定内存类型仅允许设备访问内存。内存类型不能同时设置VK_MEMORY_PROPERTY_LAZILY_ALLOCATED_BIT和VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT。另外,对象的后备内存可以由在惰性分配内存中指定的lazy实现提供。
- VK_MEMORY_PROPERTY_PROTECTED_BIT: 指定内存类型仅允许设备访问内存,并允许受保护的队列操作访问内存。内存类型不能设置VK_MEMORY_PROPERTY_PROTECTED_BIT和任何VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT、VK_MEMORY_PROPERTY_HOST_COHERENT_BIT或VK_MEMORY_PROPERTY_HOST_CACHED_BIT。
- VK_MEMORY_PROPERTY_DEVICE_COHERENT_BIT_AMD: 指定对这种内存类型分配的设备访问将自动变为可用和可见的。
- VK_MEMORY_PROPERTY_DEVICE_UNCACHHED_BIT_AMD: 指定用这种类型分配的内存不会缓存到设备上。非缓存设备内存总是设备一致的。
2.3 缓冲区拷贝函数
内存传输操作使用命令缓冲区执行,就像绘制命令一样。因此,首先分配一个临时的命令缓冲区。您可能希望为这些短期缓冲区创建一个单独的命令池,因为实现可能能够应用内存分配优化。在这种情况下,您应该在生成命令池期间使用VK_COMMAND_POOL_CREATE_TRANSIENT_BIT标志。
1 | void copyBuffer(VkBuffer srcBuffer, VkBuffer dstBuffer, VkDeviceSize size) { |
拷贝缓冲指令的一般流程是:
- vkAllocateCommandBuffers 创建指令缓冲,分配内存
- vkBeginCommandBuffer 开始指令记录
- vkCmdCopyBuffer 执行具体指令
- vkEndCommandBuffer 结束指令记录
- vkQueueSubmit 将指令提交到管道
- vkQueueWaitIdle 等待管道执行指令,也可以通过fence机制
- vkFreeCommandBuffers 释放指令缓冲区
2.2.1 vkCmdCopyBuffer 拷贝缓冲区
在缓冲区对象之间复制数据,调用:vkCmdCopyBuffer
1 | void vkCmdCopyBuffer( |
- commandBuffer是命令将被记录到的命令缓冲区。
- srcBuffer是源缓冲区。
- dstBuffer是目标缓冲区。
- regionCount是要复制的区域数。
- pRegions是一个指向VkBufferCopy结构体数组的指针,该数组指定了要复制的区域。
2.3 缓冲区拷贝
1 | void createVertexBuffer() { |
在这里思考一下,为什么要使用一个暂存缓冲区替换原来的直接使用memcpy呢,而且使用暂存缓冲还额外多了一个创建缓冲区的操作?
因为图形管道使用顶点数据缓冲区时,如果需要更改顶点数据内容,还需要等待memcpy,如果使用暂存缓冲区,可以将更改顶点数据内容的操作放在另一个线程执行,等到写完之后,再使用vkCmdCopyBuffer指令拷贝内存数据,这样图形管道最多等待这个指令拷贝的时间。当然这一点现在看不出来优势,等我们的顶点数据多而且绘制内容复杂的时候就可以体现出来了。
让我们更近一步,考虑到每次拷贝都需要执行vkAllocateCommandBuffers分配内存,不如一开始就请求一块合适的内存区域,毕竟这个函数开销还是很大的。通过使用我们在许多函数中看到的偏移参数,在许多不同的对象之间分割单个分配或回收。可以自己实现也可以使用GPUOpen倡议提供的VulkanMemoryAllocator库。
三. 索引缓冲区
在真实世界的应用程序中渲染的3D网格经常会在多个三角形之间共享顶点。比如画一个矩形: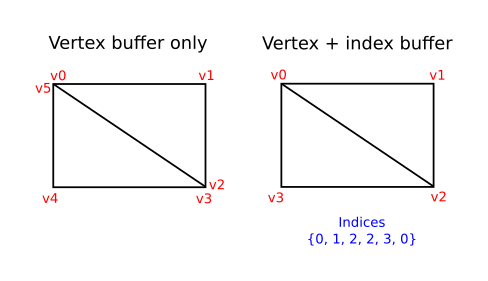
绘制一个矩形需要两个三角形(基本绘制单元只有点、线和三角形,所以矩形是两个三角形之和),这意味着需要有6个顶点的顶点缓冲区。问题是两个顶点的部分数据重复,会产生50%的冗余。在更复杂的网格中,只会变得更糟,因为顶点会在平均3个三角形中重复使用。解决这个问题的方法是使用索引缓冲区。
索引缓冲区本质上是一个指向顶点缓冲区的指针数组。它允许重新排序顶点数据,并为多个顶点重用现有数据。上面的插图演示了一个顶点缓冲区包含四个不同的顶点,其索引缓冲区会是什么样子的。前三个索引定义了右上角的三角形,后三个索引定义了左下角三角形的顶点(顺时钟)。
3.1 创建索引缓冲区
接下来将修改顶点数据并添加索引数据来绘制一个矩形,像上图中一样。修改顶点数据以表示四个角:
1 | const std::vector<Vertex> vertices = { |
左上角是红色的,右上方是绿色的,右下角是蓝色的,左下角是白色的。现在添加一个新的数组索引来表示索引缓冲区的内容,匹配图中的索引来绘制右上三角形和左下三角形。
1 | const std::vector<uint16_t> indices = { |
可以使用uint16_t或uint32_t作为索引缓冲区,这取决于顶点中条目的数量。我们可以坚持uint16_t现在,因为我们使用少于65535唯一顶点。
就像顶点数据一样,索引需要上传到VkBuffer中,GPU才能访问它们。定义两个新的类成员来保存索引缓冲区的资源:
1 | VkBuffer indexBuffer; |
可以看到 createIndexBuffer 几乎和 createVertexBuffer 一样,只有bufferSize和VkBufferUsageFlags不同而已,毕竟都是只是缓冲区。
索引缓冲同样也需要显示销毁:
1 | void cleanup() { |
3.2 使用顶点缓冲
使用索引缓冲区绘制涉及createCommandBuffers的两个更改。我们首先需要绑定索引缓冲区,就像我们对顶点缓冲区所做的那样。但是索引缓冲区只能有一个。而且,不可能对每个顶点属性使用不同的索引,所以即使只有一个属性发生变化,仍然需要完全复制顶点数据。
索引缓冲区与vkCmdBindIndexBuffer绑定,vkCmdBindIndexBuffer包含索引缓冲区、其中的字节偏移量和索引数据类型作为参数。如前所述,可能的类型是VK_INDEX_TYPE_UINT16和VK_INDEX_TYPE_UINT32。
仅仅绑定索引缓冲区还不能改变任何东西,我们还需要更改绘图命令来告诉Vulkan使用索引缓冲区。移除vkCmdDraw,并用vkCmdDrawIndexed替换:
1 | VkBuffer vertexBuffers[] = {vertexBuffer}; |
对vkCmdDrawIndexed函数的调用非常类似于vkCmdDraw。前两个参数指定索引的数量和实例的数量。我们没有使用实例,所以只指定一个实例。索引的数量表示将被传递到顶点缓冲区的顶点的数量。下一个参数指定到索引缓冲区的偏移量,使用值1将导致显卡从第二个索引开始读取。倒数第二个参数指定要添加到索引缓冲区中的索引的偏移量。最后一个参数指定了实例化的偏移量。
四. 绘制命令概述
绘制命令大致分为两类:非索引绘图命令和索引绘图命令。
4.1 非索引绘图命令
非索引绘图命令为顶点着色器提供一个连续的vertexIndex。顺序索引是由设备自动生成的,这些命令有:
- vkCmdDraw
- vkCmdDrawIndirect
- vkCmdDrawIndirectCount
- vkCmdDrawIndirectCountKHR
- vkCmdDrawIndirectCountAMD
4.1.1 vkCmdDraw
vkCmdDraw可以记录一个非索引的绘制,其原型如下:
1 | void vkCmdDraw( |
- commandBuffer是命令记录到的命令缓冲区
- vertexCount是要绘制的顶点数
- instanceCount是要绘制的实例数量
- firstVertex是绘制的第一个顶点的索引
- firstInstance是绘制的第一个实例的实例ID
执行该命令时,将使用当前基本体拓扑和顶点计数连续顶点索引(第一个顶点索引值等于第一个顶点)组装基本体。原语绘制实例数量为instanceCount,instanceIndex从firstInstance开始,每个实例依次递增。组装原语的执行要绑定到图形管道。
4.1.2 vkCmdDrawIndirect
vkCmdDrawIndirect用于记录非索引的间接绘制,其原型如下:
1 | void vkCmdDrawIndirect( |
- commandBuffer是记录命令的命令缓冲区
- buffer是包含绘图参数的缓冲区
- offset是参数开始的缓冲区中的字节偏移量
- drawCount是要执行的绘制数,可以为零
- stride是连续绘图参数集之间的字节步幅
vkCmdDrawIndirect的行为与vkCmdDraw类似,不同的是参数是在执行过程中由设备从缓冲区读取的。drawCount绘制由命令执行,参数从缓冲区的偏移量开始,每次绘制时按步长字节递增。每次绘制的参数都编码在一个VkDrawIndirectCommand结构数组中。如果drawCount小于或等于1,则忽略stride。
4.1.3 vkCmdDrawIndirectCount、vkCmdDrawIndirectCountKHR、vkCmdDrawIndirectCountAMD
记录来自缓冲区的draw调用计数的非索引绘制调用,可以使用vkCmdDrawIndirectCount,vkCmdDrawIndirectCountKHR或者vkCmdDrawIndirectCountAMD, 这三个指令几乎等效:
1 | void vkCmdDrawIndirectCount( |
- commandBuffer是记录命令的命令缓冲区
- buffer是包含绘图参数的缓冲区
- offset是参数开始的缓冲区中的字节偏移量
- countBuffer是包含绘图计数的缓冲区
- countBufferOffset是开始绘制计数的字节偏移到countBuffer中
- maxDrawCount指定将执行的最大绘制数。实际执行的绘制调用数是countBuffer和maxDrawCount中指定的最小计数
- stride是连续绘图参数集之间的字节步幅
vkCmdDrawIndirectCount的行为与vkCmdDrawIndirectCount类似,只是在执行期间设备从缓冲区读取绘制计数。该命令将从位于countBufferOffset的countBuffer中读取一个无符号32位整数,并将其用作绘图计数。
4.2 索引绘图命令
索引图形命令从索引缓冲区读取索引值,并使用此命令计算顶点着色器的vertexIndex值。这些命令有:
- vkCmdDrawIndexed
- vkCmdDrawIndexedIndirect
- vkCmdDrawIndexedIndirectCount
- vkCmdDrawIndexedIndirectCountKHR
- vkCmdDrawIndexedIndirectCountAMD
4.2.1 vkCmdDrawIndexed
vkCmdDrawIndexed可以记录一个索引的绘制,其原型如下:
1 | void vkCmdDrawIndexed( |
- commandBuffer是命令记录到的命令缓冲区
- indexCount是要绘制的顶点数
- instanceCount是要绘制的实例数
- firstIndex是索引缓冲区中的基索引
- vertexOffset是在索引到顶点缓冲区之前添加到顶点索引的值
- firstInstance是要绘制的第一个实例的实例ID
在执行该命令时,使用当前基元拓扑和indexCount顶点组装基元,这些顶点的索引是从索引缓冲区检索的。索引缓冲区被视为一个紧凑封装的大小无符号整数数组,该整数由vkCmdBindIndexBuffer::indexType形参定义,该形参与该缓冲区绑定。
第一个顶点索引位于绑定索引缓冲区中的firstIndex * indexSize + offset的偏移量,其中offset是由vkCmdBindIndexBuffer指定的偏移量,indexSize是由indexType指定的类型的字节大小。从索引缓冲区中连续的位置检索后续的索引值。索引首先与原始的重启值比较,然后0扩展到32位(如果indexType是VK_INDEX_TYPE_UINT8_EXT或VK_INDEX_TYPE_UINT16),并添加vertexOffset,然后再作为vertexIndex值提供。
这些原语是用从firstInstance开始的instanceIndex绘制instanceCount次数,并按顺序增加每个实例。组装的原语执行应绑定图形管道。
4.2.2 vkCmdDrawIndexedIndirect
vkCmdDrawIndexedIndirect用于记录索引的间接绘制,其原型如下:
1 | void vkCmdDrawIndexedIndirect( |
- commandBuffer是记录命令的命令缓冲区
- buffer是包含绘图参数的缓冲区
- offset是参数开始的缓冲区中的字节偏移量
- drawCount是要执行的绘制数,可以为零
- stride是连续绘图参数集之间的字节步幅
vkCmdDrawIndexedIndirect的行为与vkcmddrawindex类似,不同的是参数是在执行过程中由设备从缓冲区中读取的。drawCount绘制由命令执行,参数从缓冲区的偏移量开始,每次绘制时按步长字节递增。每次绘制的参数都编码在vkdrawindexdindirectcommand结构的数组中。如果drawCount小于或等于1,则忽略stride。
4.2.3 vkCmdDrawIndexedIndirectCount、vkCmdDrawIndexedIndirectKHR、vkCmdDrawIndexedIndirectAMD
同样的,记录来自缓冲区的draw调用计数的索引绘制调用,可以使用, 这三个指令几乎等效:
1 | void vkCmdDrawIndexedIndirectCount( |
- commandBuffer是记录命令的命令缓冲区
- buffer是包含绘图参数的缓冲区
- offset是参数开始的缓冲区中的字节偏移量
- countBuffer是包含绘制计数的缓冲区
- countBufferOffset是进入countBuffer的字节偏移量,在这里开始绘制计数
- maxDrawCount指定将执行的最大绘制数。实际执行的draw调用数是countBuffer和maxDrawCount中指定的最小计数
- stride是连续绘图参数集之间的字节步幅
vkCmdDrawIndexedIndirectCount的行为与vkCmdDrawIndexedIndirect类似,只是在执行期间设备从缓冲区读取绘制计数。该命令将从位于countBufferOffset的countBuffer中读取一个无符号32位整数,并将其用作绘图计数。
五. 小结
在上一篇文章中,我们使用顶点描述符VkVertexInputBindingDescription和VkVertexInputAttributeDescription替换了硬编码顶点,并且使用VkBuffer存储了顶点数据,好处是可随时更改顶点信息。在本文中,我们又使用了暂存缓冲优化了顶点缓冲每次都需要memcpy的弊端,还介绍了顶点索引,使得我们的程序可以画出更多的图形。
使用暂存缓冲是因为图形管道使用顶点数据缓冲区时,如果需要更改顶点数据内容,还需要等待memcpy,如果使用暂存缓冲区,可以将更改顶点数据内容的操作放在另一个线程执行,等到写完之后,再使用vkCmdCopyBuffer指令拷贝内存数据,这样图形管道最多等待这个指令拷贝的时间。当顶点数据多而且绘制内容复杂的时候就可以体现出来了。
而使用顶点索引缓冲是和顶点缓冲几乎一样的流程,只是VkBuffer创建时的VkBufferUsageFlags和size(对应的数据不同嘛)不同。
不过这里还是很好奇,顶点索引和顶点的关系,比如如果我们顶点坐标不变,顶点索引改成:
1 | // 顶点索引 |
对应的图形就变成了: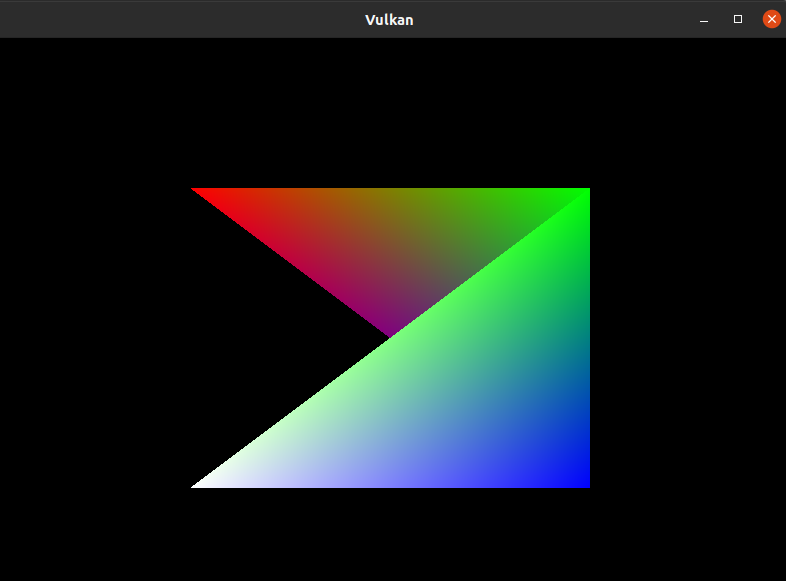
但是当顶点索引改成:
1 | // 顶点索引 |
对应的图形就变成了: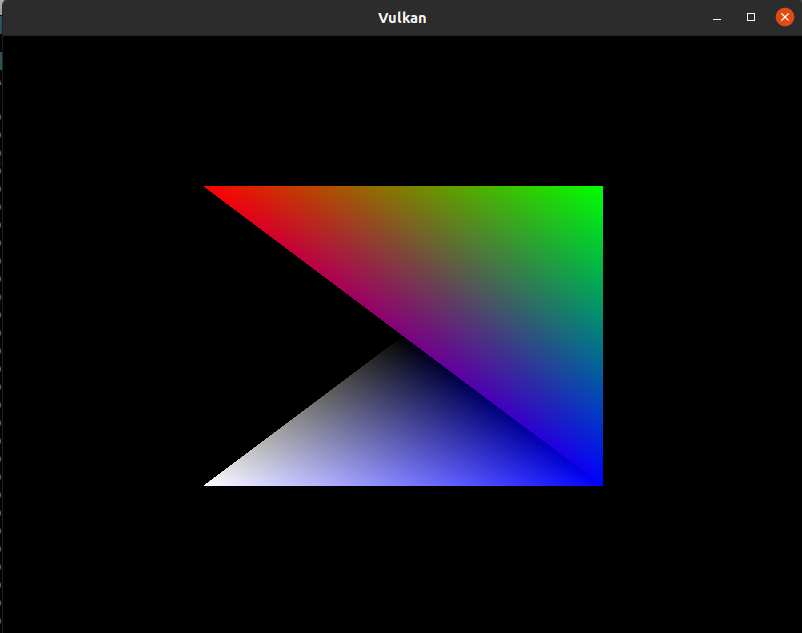
这个顶点索引和最终图像的生成到底是什么个关系呢,参考:https://zhuanlan.zhihu.com/p/97496535
Vulkan中的坐标系使用的右手坐标系,相比OpenGL是用的左手坐标系:
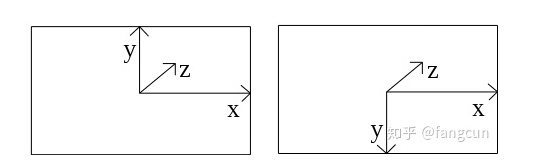
其中原点(0,0,0)在屏幕中央, 所以当我们想画一个三棱锥可以使用如下顶点及索引:
1 | // 顶点数据 |
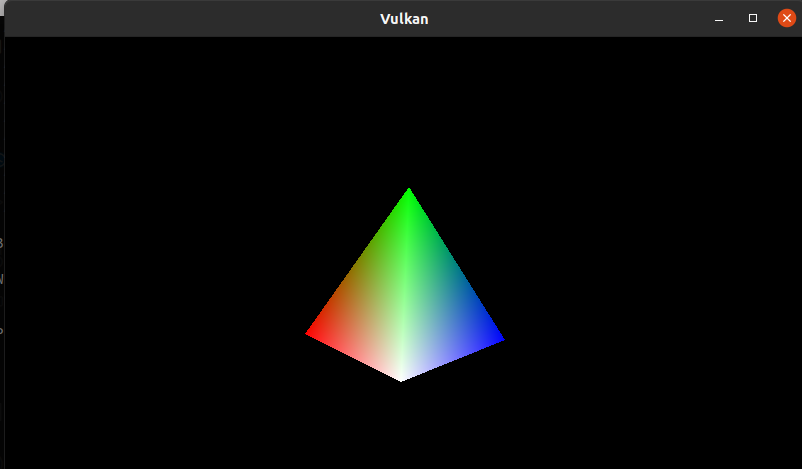
接下来,让我们再接再厉,学习使用资源描述符来加载3D图形。